Tableau comparatif des meilleurs IA LLM en 2026
Les LLM (Large Language Models) sont des modèles d’intelligence artificielle entraînés sur de très grands corpus de texte afin de prédire et générer du langage naturel. Techniquement, ils reposent sur des architectures de réseaux de neurones de type transformeur, capables de modéliser des dépendances contextuelles longues entre tokens.
Les performances d’un LLM dépendent principalement de la taille du modèle, de la qualité des données d’entraînement, de la fenêtre de contexte et des mécanismes d’alignement (instruction tuning, RLHF), qui visent à rendre ses réponses plus utiles, sûres et adaptées aux intentions de l’utilisateur.
Tableau comparatif interactif
Cliquer sur les colonnes pour trier les scores.
| Modèle ⇅ | Raisonnement ⇅ | Hallucinations ⇅ | Code ⇅ | Contexte ⇅ | Tool Calling ⇅ | Latence ⇅ | Coût (€/req) ⇅ | Multimodal ⇅ | Local ⇅ | Stabilité ⇅ |
|---|---|---|---|---|---|---|---|---|---|---|
| GPT-5 | 97/100
|
2% | 96/100 | 256K | 98/100 | 1.2s | 0.018€ 5€ in / 15€ out / 1M tok |
98/100 | 35/100 | 99/100 |
| Claude 4 Opus | 96/100
|
3% | 94/100 | 200K | 94/100 | 1.8s | 0.060€ 15€ in / 75€ out / 1M tok |
92/100 | 30/100 | 98/100 |
| Gemini 2.5 Pro | 95/100
|
4% | 96/100 | 1000K | 97/100 | 1.3s | 0.012€ 3€ in / 12€ out / 1M tok |
99/100 | 40/100 | 95/100 |
| DeepSeek R1 | 94/100
|
8% | 96/100 | 128K | 92/100 | 2.0s | 0.003€ 0.5€ in / 1.5€ out / 1M tok |
82/100 | 95/100 | 88/100 |
| Qwen 3 | 92/100
|
5% | 95/100 | 256K | 91/100 | 1.5s | 0.004€ 1€ in / 2€ out / 1M tok |
90/100 | 94/100 | 92/100 |
| Llama 4 | 91/100
|
7% | 91/100 | 128K | 87/100 | 1.1s | 0.002€ 0.4€ in / 1€ out / 1M tok |
91/100 | 98/100 | 91/100 |
| Mistral Large | 90/100
|
5% | 92/100 | 128K | 93/100 | 0.9s | 0.006€ 1.5€ in / 3€ out / 1M tok |
84/100 | 90/100 | 96/100 |
| xAI Grok 3 | 89/100
|
9% | 89/100 | 128K | 85/100 | 0.8s | 0.010€ 2.5€ in / 7€ out / 1M tok |
88/100 | 28/100 | 86/100 |
| Phi-4 | 87/100
|
5% | 90/100 | 64K | 80/100 | 0.7s | 0.001€ 0.2€ in / 0.8€ out / 1M tok |
70/100 | 99/100 | 90/100 |
| Command R+ | 86/100
|
4% | 85/100 | 256K | 95/100 | 1.0s | 0.005€ 1€ in / 2.5€ out / 1M tok |
78/100 | 88/100 | 95/100 |
Lecture des scores
95–100 : performance de pointe (frontier models)
90–94 : excellent
85–89 : très solide
<85 : plus spécialisé ou limité
Méthodologie
Raisonnement : GPQA, MMLU, ARC-AGI.
Code : SWE-Bench et HumanEval.
Hallucinations : TruthfulQA et tests de factualité.
Local : performance GGUF et quantization 4-bit.
Les scores présentés correspondent à des estimations comparatives synthétiques établies à partir de benchmarks publics reconnus entre 2025 et 2026, notamment GPQA, MMLU, ARC-AGI, SWE-Bench, HumanEval et TruthfulQA, complétés par des observations réelles en environnement de production. Ces évaluations mesurent différents axes techniques tels que le raisonnement, la fiabilité factuelle, les capacités de programmation, la cohérence contextuelle et la robustesse globale des modèles.
Les résultats doivent être interprétés comme des indicateurs comparatifs et non comme des mesures absolues. Les performances réelles peuvent varier selon la version du modèle, l’infrastructure matérielle, les paramètres d’inférence, la taille du contexte, les optimisations appliquées et le type de tâche exécutée.
Analyse structurelle de l’écostystème des modèles généralistes :
Le comparatif met en évidence une structuration désormais mature du marché des LLM en 2026. Celui-ci s’organise selon une hiérarchie en trois niveaux de performance, avec un noyau de modèles de très haut niveau, un ensemble intermédiaire compétitif et une dernière catégorie de modèles spécialisés. Cette organisation reflète une évolution vers une spécialisation progressive des architectures, plutôt qu’une simple course à la performance globale.
Les modèles les plus avancés présentent une forte convergence sur les capacités de raisonnement et de génération de code. Les écarts entre systèmes frontaliers deviennent relativement faibles sur ces dimensions, ce qui suggère une forme de saturation des gains sur les tâches générales. Autrement dit, les améliorations récentes ne se traduisent plus par des sauts qualitatifs majeurs, mais par des optimisations marginales et des raffinements de cohérence.
Dans ce contexte, les différences les plus significatives ne se situent plus uniquement dans la performance brute, mais dans les compromis techniques propres à chaque modèle. Ceux-ci concernent notamment la fiabilité des réponses (réduction des hallucinations), la capacité de traitement de contexte long, le coût d’inférence, ainsi que la spécialisation fonctionnelle sur certains types de tâches comme le tool calling ou le multimodal.
Les modèles de premier plan tendent ainsi vers une homogénéisation de leurs performances globales, avec des profils de plus en plus équilibrés entre les différents axes d’évaluation. À l’inverse, les modèles intermédiaires et spécialisés se différencient davantage par des optimisations ciblées, privilégiant certains usages spécifiques au détriment d’une performance uniforme sur l’ensemble des critères.
Cette évolution traduit un basculement structurel de l’écosystème : la supériorité d’un modèle ne peut plus être définie par un score unique ou un classement global, mais par sa position dans un espace de contraintes multidimensionnel. La performance devient ainsi un compromis entre efficacité, coût, robustesse et spécialisation, plutôt qu’une métrique isolée.
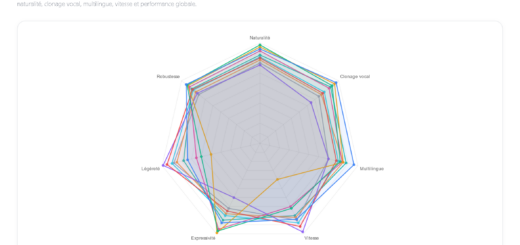
Focus sur les modèles LLM open-source
À partir du panorama général des modèles de langage, cette section se concentre sur un sous-ensemble spécifique : les modèles open-source (ou open-weight). Ces modèles constituent une alternative importante aux systèmes propriétaires, en offrant un accès aux poids du modèle, une plus grande flexibilité de déploiement et un contrôle renforcé de l’infrastructure d’exécution.
L’objectif de cette analyse est d’évaluer leurs performances selon des critères homogènes et directement comparables.
Méthodologie du graphique
Les scores sont construits à partir de benchmarks publics (GPQA, MMLU, ARC-AGI, SWE-Bench, HumanEval, TruthfulQA) et de tests empiriques 2025–2026.
Ils permettent une comparaison relative des performances sur quatre axes : raisonnement, code, maths et capacité générale.
Il ne s’agit pas de valeurs absolues mais d’indicateurs normalisés.
Conclusion :
L’analyse du comparatif des dix principaux modèles LLM open-source met en évidence une structuration désormais mature de l’écosystème. Contrairement aux générations précédentes où les écarts de performance étaient fortement marqués, les modèles actuels se distribuent selon un spectre plus continu, avec un noyau restreint de systèmes très performants et une longue traîne de modèles compétitifs mais plus spécialisés.
Un premier résultat majeur concerne la forte corrélation entre les performances en raisonnement, en génération de code et le score global. Les modèles les mieux classés sont systématiquement ceux qui maintiennent un niveau élevé sur ces trois dimensions, ce qui suggère que la capacité de raisonnement multi-étapes constitue aujourd’hui le facteur structurant principal de performance. Dans ce cadre, la compétence en programmation apparaît comme un indicateur particulièrement robuste de cohérence logique générale, dépassant son simple rôle applicatif.
À l’inverse, les performances en mathématiques demeurent plus hétérogènes et constituent le principal facteur de différenciation entre modèles de haut niveau. Contrairement au code, qui tend à être corrélé aux autres dimensions, les capacités mathématiques semblent encore dépendre de mécanismes d’entraînement plus spécifiques et moins généralisables. Cette dissociation suggère que la formalisation stricte du raisonnement reste un défi partiellement non résolu dans les architectures actuelles.
Le score global, bien qu’utile pour une lecture synthétique, tend à lisser des différences significatives entre modèles. Plusieurs systèmes affichant des performances globalement proches présentent en réalité des profils de compétences distincts, avec des spécialisations marquées selon les tâches. Cette observation confirme que les modèles open-source récents ne s’organisent plus selon une hiérarchie stricte, mais selon une logique de convergence partielle et de différenciation fonctionnelle.
Enfin, l’ensemble des résultats indique une tendance nette à la convergence des modèles de premier plan. Les écarts de performance entre les meilleurs systèmes deviennent marginaux, ce qui suggère un déplacement de la compétition vers des optimisations fines plutôt que des ruptures architecturales majeures. L’écosystème open-source entre ainsi dans une phase de maturité où l’enjeu principal n’est plus la supériorité globale, mais la spécialisation et la robustesse sur des classes de tâches bien définies.